Speaker change detection is the task of dividing a speech signal into speaker-homogeneous segments. In order to achieve this, the original signal is partitioned in consecutive small windows and we have to check how similar any two consecutive windows are. If they look similar enough, they are considered to belong to the same speaker. Otherwise, a speaker change point has been identified!
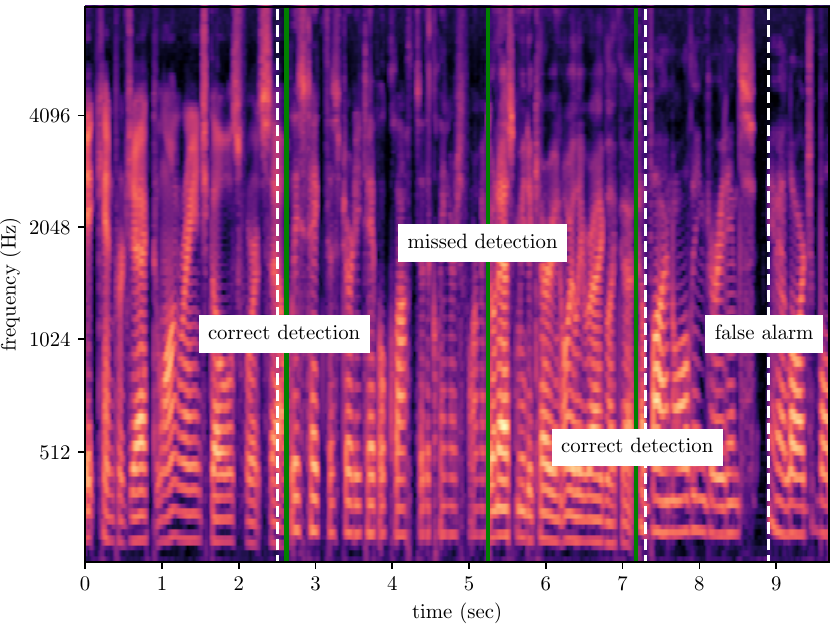
Mel-spectrogram of a speech signal with annotated timestamps of the true speaker turns (solid green lines) and the speaker turns predicted by a hypothetical speaker change detector (dashed white lines). The correct detections are denoted assuming that a reasonable tolerance margin is applied.
Following the definition of the problem, the research efforts in this field are focused on finding similarity metrics suitable for the particular task. Instead of trying to mathematically define such distance metrics, we can follow a data-driven approach and let a Deep Neural Network (DNN) architecture do the job. In this fun project, done as part of the requirements for the class “Deep Learning and its Applications”, offered at USC in Fall 2017, I use siamese Convolutional Neural Nets (CNNs) experimenting with different system designs to tackle the problem. Siamese architectures have been introduced aiming exactly at learning a similarity metric between two inputs—originally applied on computer vision problems—and, as such, offer an ideal framework for the task of speaker change detection. You can find more information on the methods and the results visiting my project page.