Speaker identification is the task of determining the identity of the person uttering a particular phrase, assuming a finite set of pre-enrolled speakers is given. Applying a continuous automatic speaker identification system on recorded meetings with multiple participants is the main problem I was working on during my 2019 summer internship at Microsoft, under the supervision of Dr. Dimitrios Dimitriadis. The successful application of such a system can significantly affect the performance of several downstream applications, such as rich transcription, speaker tracking, and action item generation.
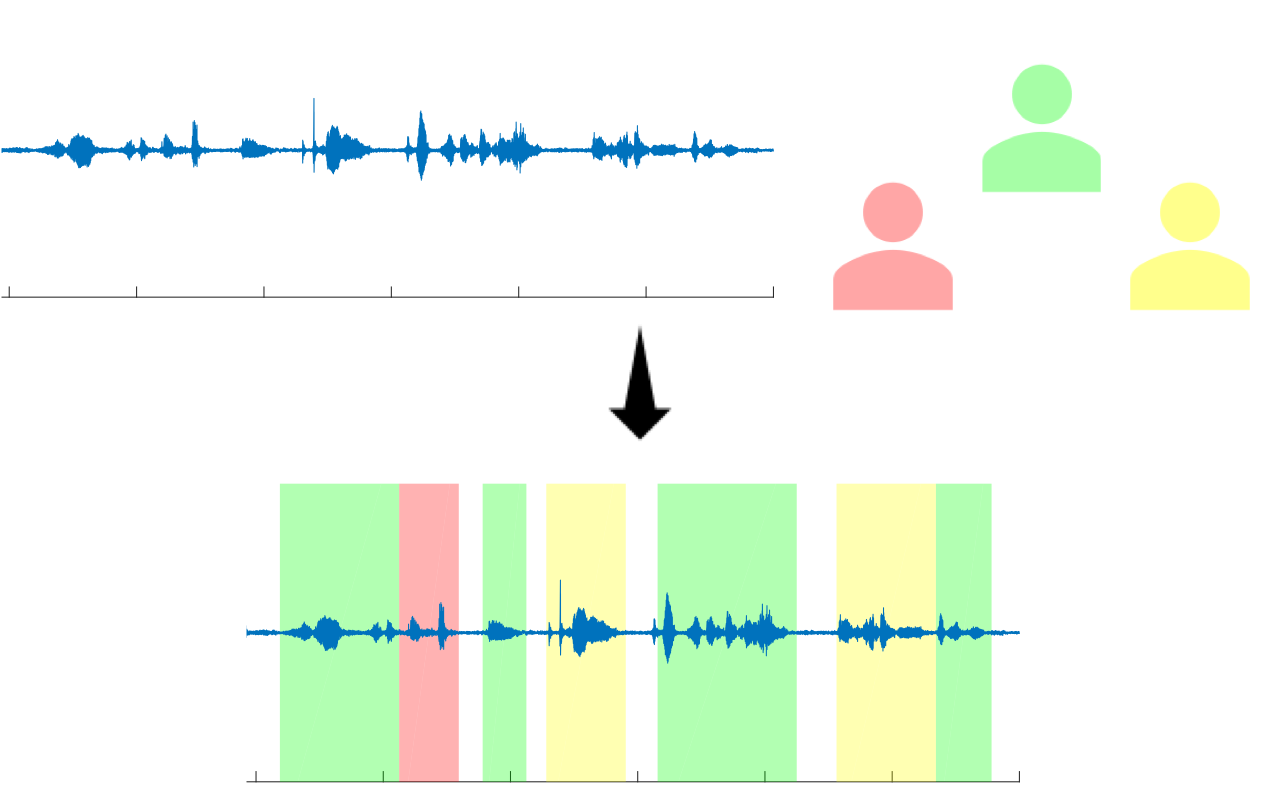
Continuous speaker identification: the speech signal is segmented into speaker-homogeneous segments, each one of which is given a speaker label corresponding to one of the available pre-enrolled speakers.
I mainly focused on architectures employing memory-augmented neural networks (MANNs), a deep learning paradigm that has shown promising results on several problems requiring relational reasoning. Speaker identification can be seen as a member of this class of tasks, since the final decision depends on the distance relations between speech segments and speakers’ acoustic identities. Under this viewpoint, we proposed a recurrent, memory-based system, able to robustly encode the distance relations, outperforming traditional distance metrics, such as the cosine distance. We evaluated our method both on scripted and on real-world meeting scenarios, achieving consistent and substantial improvements in performance. The system and the relevant analysis are presented in this paper.