Sophisticated techhniques for acoustic and language modeling have resulted in Automatic Speech Recognition (ASR) systems which can even beat human performance under clean conditions, with the speech signal typically represented by the Mel-Frequency Cepstrum Coefficients (MFCCs). However, when the speech signal is distorted by background noise or reverberation there is ususally a severe performance drop. Such distortions are unavoidable when the recording microphone is moved away from the speaker’s mouth; thus a challenge of finding more robust representations of the signal for the task of distant speech recognition arises.
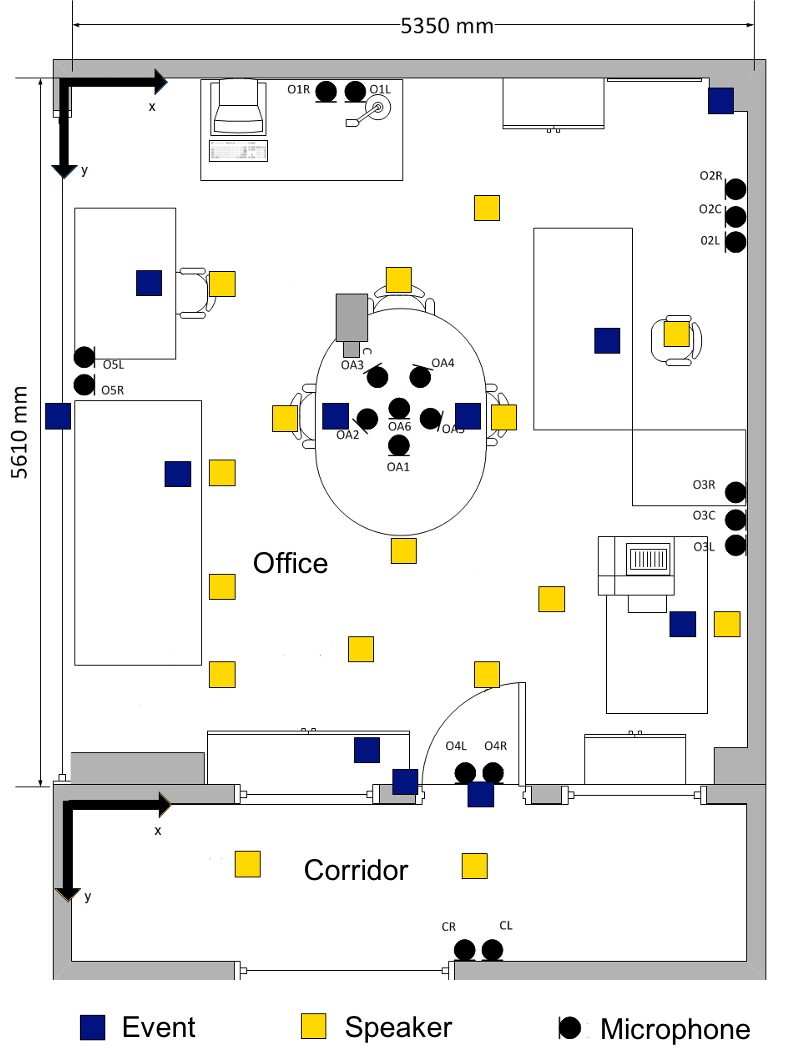
Floor plan of the environment where ATHENA dataset was recorded. ATHENA is a collection of Greek speech recordings that I used for my experiments on robust speech recognition.
Image adapted from Tsiami et. al., ATHENA: a Greek multi-sensory database for home automation control, Interspeech, 2014.
In this research thread, which is the subject of my Diploma thesis, supervised by Professor Petros Maragos, my focus is on the comparative study of widely used acoustic feature sets as well as on the usage of the Teager-Kaiser Energy Operator (TKEO) as an alternative approach for estimating the energy of a speech signal. To this latter direction, I have proposed a new framework where TKEO is used in the frequency domain, aiming at the reduction of computational complexity, and I have used it for the extraction of the instantaneous amplitude and frequency, exploring acoustic features motivated by the AM-FM model of speech.